딥러닝 모델 CS-Flow의 구조와 특징
Fully Convolutional Cross-Scale-Flows for Image-based Defect Detection를 읽고 작성하였습니다.
요약
CS-Flow는 fully convolutional Cross-Scale normalizing Flow를 뜻하며,
정상 이미지만을 학습해 이상치를 탐지하는 Anomaly Detection 모델 중 하나이다.
CS-Flow의 가장 큰 특징은 input 이미지 resize를 통해 3가지 크기의 이미지를 생성하고, 이를 동시에 연산하여 확률 분포를 생성한다는 것이다. 이 방법을 통해 fine-grained positional and contextual information, 즉 세밀한 위치 정보와 의미 정보를 유지할 수 있다고 한다.
Architecture
전체 구조
전체적인 CS-Flow의 구조는 다음과 같다. 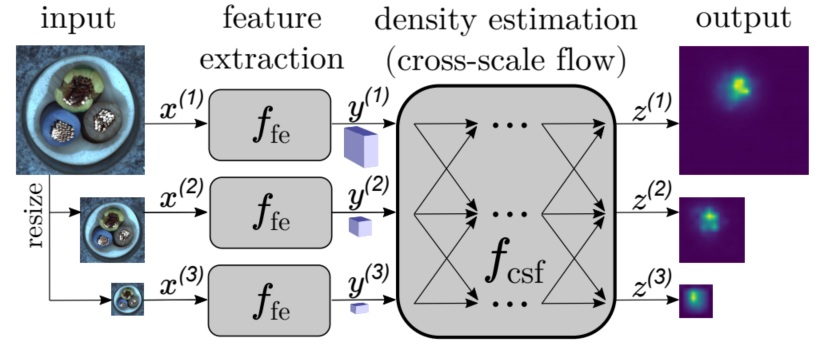
- input 이미지가 3가지 크기로 resize된다.
- 크기가 다른 3가지 이미지들[\(x^{(1)}, x^{(2)}, x^{(3)}\)]은 feature extraction 과정을 거쳐
3차원 feature map [\(y^{(1)}, y^{(2)}, y^{(3)}\)]으로 변환된다. 이때, extractor로는 논문에서 EfficientNet-B5를 사용하였으며, 이외의 다른 pretrained neural network를 사용할 수 있다. - 이후 feature map들이 normalizing flows 과정을 거치면, 확률 분포 \(p_{Z}\)가 계산 된다. CS-Flow에서 사용되는 normalizing flows는 cross-scale flow로, 기존의 normalizing flows의 확장된 버전이다.
- 학습 과정에서는 최적의 확률 분포 \(p_{Z}\)를 찾고, 테스트 단계에서 확률 분포 \(p_{Z}\)를 이용해 likelyhood \(p_{Z}(z)\)를 도출하고 threshold 와 비교해 정상/비정상을 판단한다. (\([z^{(1)}, z^{(2)}, z^{(3)}]=z\))
Normalizing Flows with Cross-Scale Flow
다음은 CS-Flow의 Normalizing Flows의 block 구조이다. 점선으로 둘러쌓인 부분을 하나의 coupling block이라고 부르며, 논문에는 이 block을 4~5번 반복하는 것이 가장 좋다고 되어 있다. (실제로 테스트해본 결과, coupling block을 1개만 사용해도 성능이 매우 좋았고 모델 크기는 더 작았다.)
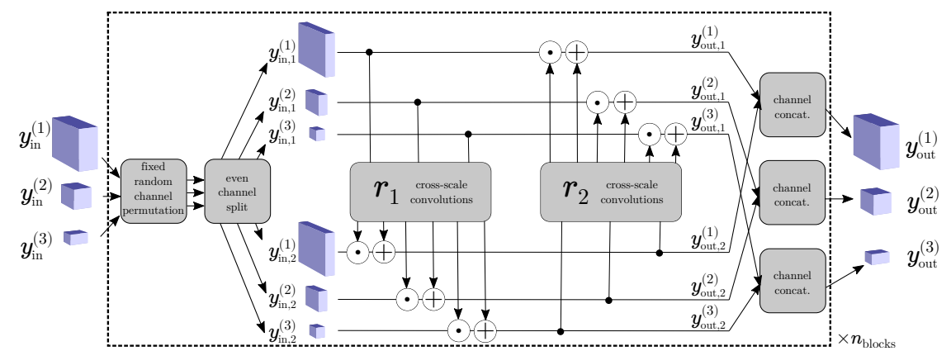
먼저 channel이 절반으로 나뉘어 위쪽, 아래쪽으로 분리된다. 분리된 tensor들은 반대쪽 tensor에 영향을 주는 parameter들(scale, shift)을 구하는 cross-scale convolutions(\(r_{1}\)과 \(r_{2}\))에 사용된다. subnetwork \(r_{1}\)과 \(r_{2}\)는 각각 \([s_{1}, t_{1}]\)와 \([s_{2}, t_{2}]\)를 반환하는데, 이때 \(s_{i}\)는 scale parameter이고, \(t_{i}\)는 shift paramter이다.
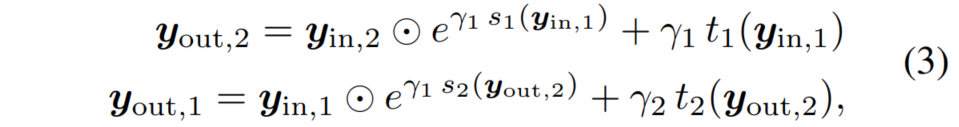
위의 식처럼 scale parameter \(s_{i}\)은 element-wise product 연산(\(\odot\))에 사용되고, shift parameter \(t_{i}\)는 element-wise sum 연산(+)에 사용되며 \(y_{out, i}\)이 결정된다. 그 후 나뉘었던 channel이 다시 합쳐지며 \(y_{out}\)이 구해진다.
Cross-Scale Convolutions
위의 Normalizing flows에서 \(r_{1}\)과 \(r_{2}\)에 해당하는 부분을 자세히 나타낸 것이다.
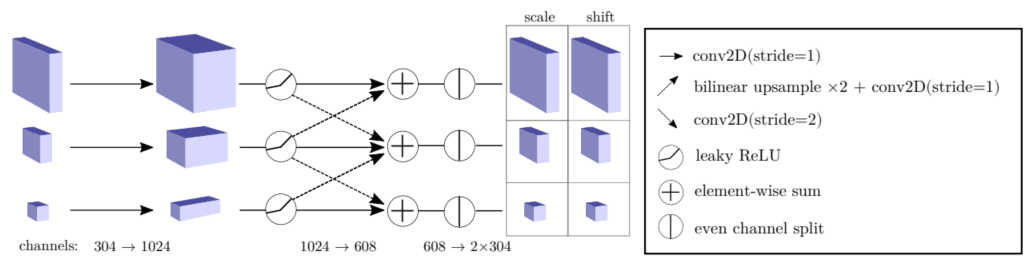
총 두 단계의 convolution이 이루어지는데, 첫 번째는 일반적인 2D convolution이고 두 번째가 cross convolution이다. cross convolution에서 크기가 다른 feature map들을 연산해 더하려면 크기를 똑같이 맞춰줘야 하기 때문에 stride를 조절하거나 upsampling을 한다. 아래쪽으로 내려가는 화살표는 stride를 2로 설정한 convolution을 통해 크기를 반으로 줄여주는 것이고, 올라가는 화살표는 upsampling을 통해 크기를 키워준 후 convolution하는 것이다. 두 단계의 convolution 후에 각 output이 element-wise로 더해지고, channel을 기준으로 절반으로 나뉘며, 각각 scale paramter와 shift paramter가 된다.
reference
https://github.com/marco-rudolph/cs-flow
https://arxiv.org/pdf/2110.02855.pdf